Simple Operators in Words

The Journey Continues
In this post, I will go through some of the basics of how I have set up my compiler to convert the AST generated by Hime into a decorated expression tree used by the compiler’s semantic analysis, and finally into a series of simple binary opcodes to be executed by the Words virtual machine.
As I mentioned in the previous post, I’m still looking at a very early stage in the language development – just a series of simple expressions involving literals and local variables. The stage we are interested in is post AST generation – Hime has informed us that the page is grammatically valid. It’s not up to the compiler to see if it actually makes sense.
At the core of the compilation system is the expression tree – Hime’s AST is not particularly useful for us as it is (essentially) a series of named nodes. While it encodes structure, it lacks all the richness of meaning. The (abridged) grammar, at this stage, is this:
exp_name -> tkIdentifier;
exp_literal -> exp_integer_literal | exp_real_literal | exp_string_literal | exp_boolean_literal;
type -> builtin_type;
exp_local_declaration -> type exp_name;
exp_local -> exp_name;
exp_lvalue -> exp_local | exp_local_declaration;
exp_parenthesized -> '(' exp_rvalue ')';
exp_cast -> '(' type ')' exp_unary;
exp_unary -> exp_literal | exp_name | exp_parenthesized | exp_cast;
exp_multiply -> exp_multiplicative '*' exp_unary;
exp_divide -> exp_multiplicative '/' exp_unary;
exp_modulo -> exp_multiplicative '%' exp_unary;
exp_multiplicative -> exp_unary | exp_multiply | exp_divide | exp_modulo;
exp_binary_minus -> exp_additive '-' exp_multiplicative;
exp_binary_plus -> exp_additive '+' exp_multiplicative;
exp_additive -> exp_multiplicative | exp_binary_plus | exp_binary_minus;
exp_rvalue -> exp_additive;
exp_assignment -> exp_lvalue '=' exp_rvalue;
statement -> (exp_local_declaration | exp_assignment) ';';
statement_block -> statement*;
I’ve omitted some bits we’ve already covered (literals and types), but this shows how operator precedence is encoded.
AST to Expressions
The compiler has been given an ASTNode representing the element called “statement_block” in the above grammar. It contains zero or more children of the type “statement”, each of those contain either an “exp_assignment” or an “exp_local_declaration” as their child node, etc. Now, Hime is essentially a black box. It’s licensed under the LGPL – so we won’t be messing with their expression tree. I also am not using callbacks to respond to the parse tree as it’s generated (much like you might do when parsing a data file like JSON or the comedy YAML option), so we’re looking at a complete AST.
My plan is to convert the Hime tree into my own expression class type. This class will provide some basic interfaces such as the computed type of the expression (like an int or a float). Expression classes will be extended for each language feature, and these classes are responsible for doing the code validation as well as generating the opcodes.
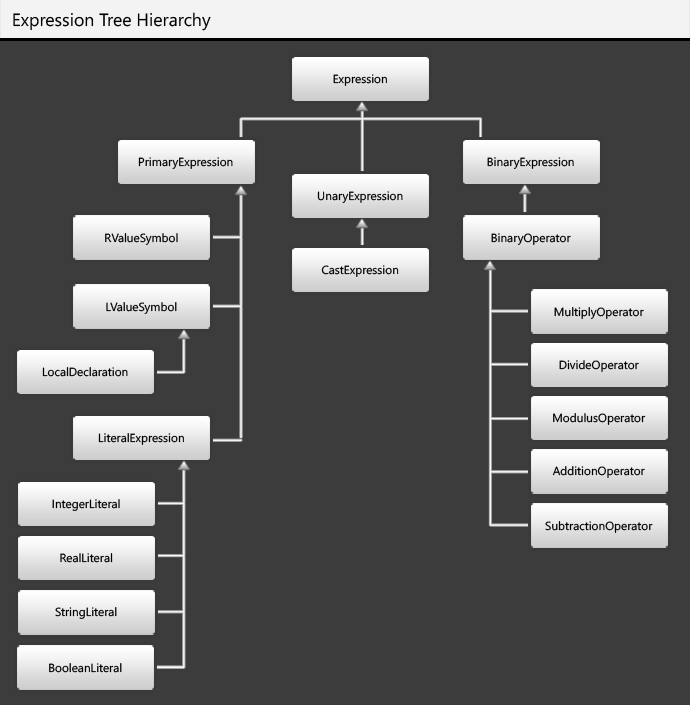
An expression tree is constructed for each statement in the block that contains our code. For expressions that have child elements (Unary and Binary expressions), the expression object constructor is invoked recursively. The key function is an extension method that I wrote called “As” – it will search down a Hime AST looking for a node of the requested type, and return that node – provided that there is only one child node at each level of the AST. As an example, with our grammar, the fragment:
5 * 7
parses as:
- exp_rvalue
- exp_additive
- exp_multiplicative
- exp_multiply
- exp_unary
- exp_literal
- exp_unary
- exp_literal
- exp_unary
- exp_multiply
- exp_multiplicative
- exp_additive
I can use the as method like this:
ASTNode node_multiply = root.As("exp_multiply"); // succeeds
ASTNode node_unary = root.As("exp_unary"); // fails, because the only unary nodes are below a node with multiple children
ASTNode node_multiply1 = node_multiply.Children[0].As("exp_unary"); // succeeds, however
// This means the AST->expression code is able to do this:
ASTNode addNode = root.As("exp_binary_add");
if (addNode != null)
{
return new AdditionOperator(addNode,
ConstructExpression(addNode.Children[0]),
ConstructExpression(addNode.Children[2])); // Children[1] is '+'
}
And so on for each operator. In the example with the AdditionOperator, because it is a binary operator with two children, two additional expressions are needed as arguments in the constructor – these come from further invocations of the AST->expression function (“ConstructExpression”).
Once we have our own expression classes generated, we can begin to do some actual semantic analysis. I have done this by giving each expression a virtual method (“Fold”, because of constant-expression folding, although it’s probably misnamed), where the expression is allowed to perform checks, and possibly even return an entirely different expression back – so, for example an AdditionOperator may see that both its left and right children are IntegerLiterals. During the Fold() process, it should return a new IntegerLiteral with the sum of the two child nodes. This folding operation is done depth first. An example for the Fold() operation for a binary operator is this – SimplifyLiteral is virtual and dealt with via the inherited classes.
public override Expression Fold()
{
Left = Left.Fold();
Right = Right.Fold();
if (Left.IsLiteral && Right.IsLiteral)
{
LiteralExpression left = Left as LiteralExpression;
LiteralExpression right = Right as LiteralExpression;
return SimplifyLiteral(left, right);
}
return this;
}
Ideally, once the Fold() operation is completed, the statement should be valid (any errors should be generated earlier, as that is where you have the best chance at introspection), and ready for code generation.
Builtin Types Redux
Amazingly, we’re back on a familiar topic, types and conversions. You see, the simple operators that we’re dealing with could actually be reasonably complex in their type behaviour – and we need explicit rules, or – as I have mentioned before – we will fall into the pit of PHP, and madness that way lies.
So – we need to come up with some sensible rules. Remember, we’re not specifying the result type, per se – we are specifying the type that the calculation is performed with. As such, we need to select a format which is most able to represent the gamut of results. For narrow integer types, this is pretty straightforward – these are already represented as 32-bit signed integer types on the stack. For floats and doubles, they will always be more representative than integers (although potentially less accurate), making them the intermediate (and result) type for any operations.
The problems arise when we look at the 32- and 64-bit integer types. Words is not a language which checks for (or is concerned with) overflow in results – that said, we will duplicate a few rules established by C#. When operating on a mixture of signed and unsigned values, the integer type is promoted to a wider, signed format. This means that a mixture of a uint and any signed type will result in a long. Where no promotion is available (e.g., ulong and long), the operation produces a compile time error.
Finally, for consistency with C (this rule is also used by C#), any operation involving two operands of the same type will produce a result of the same type. The resulting type table is shown below:
| Operand Result Types | ||||||||||
| Type | s8 | u8 | s16 | u16 | s32 | u32 | s64 | u64 | f32 | f64 |
| s8 | s32 | s32 | s32 | s32 | s32 | s64 | s64 | — | f32 | f64 |
| u8 | s32 | s32 | s32 | s32 | s32 | u32 | s64 | u64 | f32 | f64 |
| s16 | s32 | s32 | s32 | s32 | s32 | s64 | s64 | — | f32 | f64 |
| u16 | s32 | s32 | s32 | s32 | s32 | u32 | s64 | u64 | f32 | f64 |
| s32 | s32 | s32 | s32 | s32 | s32 | s64 | s64 | — | f32 | f64 |
| u32 | s64 | s32 | s64 | s32 | s64 | u32 | s64 | u64 | f32 | f64 |
| s64 | s64 | s64 | s64 | s64 | s64 | s64 | s64 | — | f32 | f64 |
| u64 | — | u64 | — | u64 | — | u64 | — | u64 | f32 | f64 |
| f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f64 |
| f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 |
These rules can, depending on your perspective, be reasonably sane or quite arbitrary. The main justification – “What Would C# Do?” – is ultimately just another arbitrary source. However, the promotion rules mean that when you’re dealing with mixed types, it should just work*There are always corner cases, but we live for the now, so stuff them!. The assumption is that if you’re not mixing your types, you know what you’re doing. Since all the calculations on narrow integer types are done in 32-bits, you will have to explicitly cast the result back down to a narrow format.
Operator Flavour and Conversions
So, the expression system can inspect the left and right child expressions to determine the result type. We therefore must emit code to convert the inputs (if required) to the result format as they get pushed onto the expression stack. Converting between signed and unsigned formats of the same width value is a no-op; the value is simply reinterpreted. When upcasting, things get a little more exciting. Upcasts need to perform different code when dealing with signed and unsigned values. As an example, when upcasting from 32- to 64-bit integers:
value = 0xFFFFFFFE; // as a uint, this is ~4bn, as an int, this is -2 Int32->Int64: // Value of -2, the sign bit is extended into the top 32 bits value = 0xFFFFFFFFFFFFFFFE; Uint32->Int64: // Value of ~4bn, the top 32 bits are zero extended value = 0x00000000FFFFFFFE;
Similarly, we must be careful when upcasting from integer types to floating-point formats. Interestingly, I don’t believe downcasting is an issue – truncation is always going to produce some fun results, but I’m pretty sure you can go from larger formats to narrower formats by simply masking off the bits you want. Downcasting from float formats to integer formats involves going to the appropriately sized signed format and then reinterpreting the result as unsigned.
There are, as ever, corner cases. We have to provide for truncating integer values while still keeping their values sensible on the stack. When we cast from an int to a sbyte, if we were simply storing the result we could slice off the lowest 8 bits and call it a day. But look at the following code:
sbyte a = 127; int r1 = (sbyte)(a + 1); // r1: -128 (0xFFFFFF80) byte b = 127; int r2 = (byte)(b + 1); // r2: 128 (0x00000080)
We need to provide truncation methods that perform sign-extension (much like upcasting methods do) to provide for the cases above (similar to loading these narrow formats into a full-sized register). The final list of conversion operators is:
- TruncateU8, TruncateS8
- TruncateU16, TruncateS16
- ConvertU32toS64, ConvertS32toS64
- ConvertU32toF32, ConvertS32toF32, ConvertU64toF32, ConvertS64toF32
- ConvertU32toF64, ConvertS32toF64, ConvertU64toF64, ConvertS64toF64
- ConvertF32toS32, ConvertF32toS64
- ConvertF64toS32, ConvertF64toS64
- ConvertF32toF64, ConvertF64toF32
Since I have already decided that the Words VM will be a stack machine, it has to deal with heterogeneous types too. It therefore isn’t sensible to have a single opcode, such as Add for performing addition – while inputs are going to be converted, the VM shouldn’t be required to introspect the stack elements to decide whether to perform (e.g.) an addition 32-bit or 64-bit integers; especially given that this information is available to the compiler.
Given the five operators, * / % + and -, three of them are “sign-agnostic”. Because of how results are truncated in CPUs, we can perform multiplication, addition and subtraction without caring if the inputs are signed or unsigned.
int a = -100; // 0xffffff9c (4294967196 as uint) int b = 100; // 0x00000064 (100 as uint) // Sign extended high precision == 0xffffffffffffd8f0 long signed = (long)a * (long)b; // == -10000 // Zero extended high precision == 0x00000063ffffd8f0 ulong unsigned = (ulong)(uint)a * (ulong)(uint)b; // == 429496719600 // Note that the lower 32 bits are identical! int x = a * b; // 0xffffd8f0 or -10000 uint x = (uint)a * (uint)b; // 0xffffd8f0 (overflows)
Similar demonstrations can be done with addition or subtraction – where signed and unsigned values differ, the results are truncated to exclude those bits. This is not the case with division, as can be trivially shown:
int a = 1; // 0x00000001 int b = -1; // 0xffffffff int signed = a / b; // 0xffffffff == -1 // This becomes zero, because (uint)b is ~4bn (2^32 - 1) // And 1 divided by ~lots~ is zero in integer maths uint unsigned = (uint)a / (uint)b; // == 0
Thus, we need, at a minimum, the following operators:
| Numeric Operand Variants | ||||||
| Type | s32 | u32 | s64 | u64 | f32 | f64 |
| Add | Add_I32 | Add_I64 | Add_F32 | Add_F64 | ||
| Subtract | Sub_I32 | Sub_I64 | Sub_F32 | Sub_F64 | ||
| Multiply | Mul_I32 | Mul_I64 | Mul_F32 | Mul_F64 | ||
| Divide | Div_S32 | Div_U32 | Div_S64 | Div_U64 | Div_F32 | Div_F64 |
| Modulus | Mod_S32 | Mod_U32 | Mod_S64 | Mod_U64 | Mod_F32 | Mod_F64 |
As a final addition (get it!) we add a special variant of “Add” for strings – because strings are, after all, a core language type.
Words Operator Precedence
The grammar encodes the operator precedence, and while I am only implementing the numeric binary operators for now, I didn’t want to refactor my grammar file later, so I added the rest of the operators I want to add. The grammar encodes the precedence, which is as follows:
| Operator Precence (Highest to Lowest) |
| Casting Operator, Unary Plus, Minus, Boolean Not and Bitwise Not |
| Increment and Decrement |
| Multiply, Divide and Modulus |
| Add and Subtract |
| Left and Right Shift |
| Bitwise And |
| Bitwise Xor |
| Bitwise Or |
| Greater-than(-or equal), Less-than(-or equal) |
| Equals and Not Equals |
| Boolean And |
| Boolean Or |
I have highlighted some rows in yellow (bitwise or… and equality operators) because this is different to C#/C++. I may renege on this plan because it’ll inevitably come back to bite me later (mark my words!). The upshot of this is visible in this code:
// This pattern is a logical way of writing code that selects for, // as an example, a some bitflags in a value, and then checks it bool test = someValue == flags & mask; // In C++, that parses as this, which is probably not what you wanted bool test = (someValue == flags) & mask; // In Words, the 'and' binds more strongly bool test = someValue == (flags & mask);
To be honest, this is a pattern I’ve used many times before, and thankfully Visual Studio emits a warning if you do that*Essentially gently telling you that you almost certainly did that wrong, which as far as I’m concerned is an admission of guilt that the parsing is probably a bit non-intuitive.
Next time, we’ll finally get onto the IL generation, as well as how locals work!
Edit: I have already been asked what my position on the following code is:
bool lolmyface = x == 0 & y == 1;
In C, this will return evaluate as true if x is zero and y is one – in Words, this will evaluate as (x == (0 & y)) == 1. I may add some functionality which restricts the implicit conversion to boolean values to not include comparisons, making this a compile-time error. Words’ somewhat exciting shakeup of the status-quo with operator precedence does not preclude making a statement without short-circuiting ‘&’ operators, but you will need to add parentheses:
bool testWithSideEffects = (x == 0) & (SideEffectFunction() == 10);
I still stand by my two prior assertions: this will undoubtedly haunt me from now on, and that people ~generally~ want &&, not &.

Trackbacks & Pingbacks