Letters from Words

From Expressions to Bytecode
Previously, we had generated a set of semantically meaningful expressions from an arbitrary (but simple) block of code (shown at the start of the post before that). In this post, I’ll go into the process of converting the tree into an intermediate language that our interpreter can understand. Of course, before we can generate instructions in this format, we need to define the format.
Introducing Letters
Words’ bytecode format, creatively named ‘Letters’ is, as I have previously mentioned, a set of instructions that operate on a stack based virtual machine. I have chosen a stack machine because I think it’ll be easier (i.e., faster) to develop, and because there is a reasonable amount of work around in translating stack machines to register machines (normally during JIT compilation) in Mono, C#, Java, Dalvik, etc – so I think there’s scope there if I need to cross that bridge later.
That said, I anticipate issues with implementing the Letters VM immediately – the biggest of these is that the stack is heterogeneous (the top of stack could be an int, or an object reference, or a string, or any of the basic types), which requires that the generated IL is explicit with types. I said previously that I would be referencing a lot of the C# IL design, but this is where Letters and CIL diverge. Stack based code also tends to be quite verbose, making what appear to be quite trivial code compile into something unexpectedly large – this is something we’ll cover later.
Requirements
I’ve defined Letters as being a series of instructions that operate on a stack. However, Letters still requires some way of addressing local variables. I am going to use the same technique as CIL – arguments and locals are addressed “off-stack” via special instructions, which means that only the top element of the stack can ever be operated upon. While this is ~strictly speaking~ an implementation detail, I will end this post with mention of the C# “reference” VM and how this is implemented.
We have previously selected a small language subset to start with, and from that we can define the necessary opcodes:
LD_LOC, // Load local variable ST_LOC, // Store a local variable // Load constant variants LDC_I4, // Load a 32 bit integer value LDC_I8, // Load a 64 bit integer value LDC_F4, // Load a 32 bit real value LDC_F8, // Load a 64 bit real value // Operators - each of these needs to specify the "flavour", I4, U4, F4 or F8 OP_ADD, OP_SUB, OP_MUL, OP_DIV, OP_MOD, RET, // to indicate the end of the method
Contexts, ILGenerator and Locals
When translating an expression tree to a procedural form, we will need to introduce a few new bits of data into our compiler. This can all be encapsulated in a single object, which I have called the Context of each expression. Expression context represents the structural location in a program. While the AST generates contextual data by placing everything in a giant tree, I’ve chosen to pull apart the “decoration” (function headers, classes etc) and the “code“. The division of course is to do with what the output is – code expressions will generate IL, decoration expressions will be consumed by the compiler and generate metadata (and containers).
While this simplifies the compiler (something I will mention again when I discuss global symbols – probably the next post), it does mean that I’ve thrown away some of this contextual data. That said, a dedicated class containing all the contextual info an expression wants is vastly more efficient than trawling through the AST every time you want to see if ‘a‘ is a “function argument” or something else. Each expression is given one of these contexts, which themselves are parented to other contexts. The top level context is owned by the compiler. Because Words is C-like in structure, you can see immediately that each block of statements is its own context (defined by the structure which ‘owns’ that block).

As an example in the mockup above, we can see several (nesting) contexts – and the expressions within those contexts can use them to derive semantic information. At the moment, we are only really concerned with two uses for contexts:
- Declare a local here (if it is legal)
- Perform a lookup on a symbol to see if it is a local (if it isn’t, it’s a compile error)
For our purposes, I scoped out a basic compiler context, and added a “function context” which allows locals to be declared. This operates in tandem with a new class, ILGenerator, to allocate/retrieve locals from contexts. While I was doing this, I decided it was probably an appropriate time to define the rules for scope and locals. In Words, variable shadowing is disallowed (it causes a compile time error), because, let’s be honest – it has never been something you want. That said, I am a compulsive copy and paster, so it should be completely legal to have multiple variables in a function with the same name – provided they aren’t in nested scopes. Thus:
int Test()
{
int a = 10;
{
int a = 50;
}
}
Generates this error:
Compilation Error:
Duplicate local definition with name "a"
C:\Development\WordsSystem\Run\Test.wds:5
4: {
5: int a = 50;
=~~~~~~~~~~^
6: }
But it’s totally legal to do this:
int Test()
{
{
int a = 10;
}
{
int a = 50;
}
}
While there are many contexts generated during compilation, there’s only one ILGenerator created for each entire function. Converting from a tree of expressions to the procedural format (for a stack machine, at least) is fairly straightforward – the tree is visited depth first, and each expression type is given a chance to output one or more instructions to the ILGenerator. Expressions with child nodes are responsible for calling the Emit() method on each child in right to left order. Expressions that represent new blocks (e.g., a scope, a loop body, etc) are responsible for recursively calling the code generation function for their subtree.
The expression tree given here shows how the expansion works:
int value = (int)(7.0f / 5.0f);
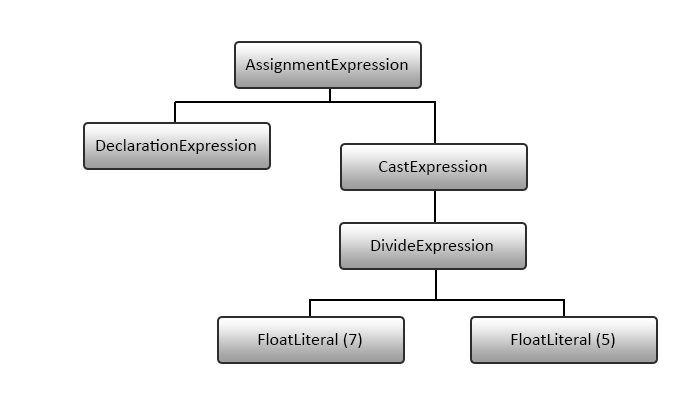
The expression tree has code generation invoked depth first. All non-terminal nodes emit children right to left – generating the following code:
LDC_F4 5.0f // generated by literal expression LDC_F4 7.0f OP_DIV (F4) // divide expression CONV_F4_I4 // cast expression ST_LOC 'value' // declaration expression (lvalue) // note that the assignment expression did not generate code
I originally went for a mixture of left-to-right and right-to-left, but decided it was all a bit arbitrary because, while it’s nice to push arguments onto the stack in reading order, it does mean that we have to reverse the order of code generation for assignment expressions. This also allows things like passing in the object pointer (for member functions) at the top of the stack, rather than having it as a hidden “last” argument, which seems a little dirty to me. Of course, the main benefit of right-to-left parameter passing comes from the variadic functions that make up C’s heritage, like printf. If all the “optional” arguments get pushed first, the function can choose to ignore them while still having access to the important arguments (the first N), which will be logically at the top of the stack. Words, however, won’t have variadic methods – or – rather, they will be dealt with like C#, as syntactic sugar over something much more mundane.
Also, in the IL I have shown above, locals are referenced by an “index” which is assigned to them as they are declared. The index represents a slot in the function’s local data memory, which is zero-initialized on function entry. There will be no dynamic lookups happening based on names or anything like that – remember, the language has to be fast.
Finalization and Example
Once all the statement expressions in a function have been through code generation, a final step is performed on the instruction stream. Firstly, this step encodes the instructions (previously a list of opcodes and arbitrary arguments) into a bytecode. While it does that, it also performs “fixups”, any case where another instruction is referenced (e.g., a jump) will be converted to a relative offset to another part of the instruction stream (measured in bytes, because the instructions are variably-sized). Going back to our initial goal, we have all the tools required to generate some opcodes, and indeed, this is the result:
Method IL
locals {
[0] Int32 'testInt'
[1] Float32 'initializedValue'
[2] Int32 'example'
[3] Int32 'truncated'
}
I#0000: LDC_F4 (10)
I#0005: ST_LOC #1 'initializedValue'
I#000A: LDC_I4 (0x00000006)
I#000F: LDC_I4 (0x00000023)
I#0014: LDC_I4 (0x00000001)
I#0019: LDC_I4 (0x0000000A)
I#001E: OP_ADD #Int4
I#0020: OP_MUL #Int4
I#0022: OP_MOD #Int4
I#0024: ST_LOC #2 'example'
I#0029: LDC_F4 (5)
I#002E: LDC_F4 (7)
I#0033: OP_DIV #Float4
I#0035: CONV_F4_I4
I#0036: ST_LOC #3 'truncated'
In fact, we have the tools to do a bit better. I’ve taken the liberty of adding a few special opcodes for loading the integers 1, 0, and -1, as well as their floating-point versions (C# has all the integers up to 10, so I suppose it must be useful to have such things!). I also put code into the expression parser to perform constant-folding and static cast conversion, which results in the code size shrinking a lot:
I#0000: LDC_F4 (10)
I#0005: ST_LOC #1 'initializedValue'
I#000A: LDC_I4_1
I#000B: ST_LOC #2 'example'
I#0010: LDC_I4_1
I#0011: ST_LOC #3 'truncated'
Reference VM
Of course, all of this is a bit academic without a VM to run it in. Luckily, C# provides an excellent framework for writing a simple (if… slow) VM for Words. Because of C#’s boxing capabilities, we can implement the execution stack as a simple Stack<object>, and rely entirely on box/unbox operations for heterogeneous storage. We will still need the “flavour” codes for each operation, as C# will happily throw exceptions if you unbox an object of the wrong type (indeed – you can’t even unbox an object from signed to unsigned or vice versa, despite that being a no-op in CIL). These rules lead to some comedy-level code like this:
case OpCode.TRUNC_S1:
stack.Push((int)(sbyte)(int)stack.Pop()); break;
Where the code has to extract an object from the stack, unbox it as an int (known because the operation is unambiguous – no introspection, remember?), truncate it to an sbyte, then widen it back to an int before it is reboxed.
In order to honour the way that Words operates, the reference VM will store elements in the stack as boxed ints, longs, floats, doubles, strings and objects. Unsigned types are always converted post boxing/unboxing, which ensures that we won’t fall afoul of C#s draconian type enforcement. Locals are implemented as a List<object> pre-allocated to zeros (or nulls) of the correct type (again, to ensure unboxing is safe). The main VM works by reading one byte from the instruction stream (the opcode), and switching to handlers for each opcode. The stream is advanced in the handler (as the instructions are variable width), and the operations are performed on the stack and the locals.
It was very easy to implement a C# VM for Words, which was gratifying – but the adventure has only just started. Next time, I will talk about Symbols, how a Book is packaged, and possibly branching. Or maybe function calls. Possibly even the BCL! Who knows!
I have uploaded the prototype C# VM’s main instruction loop for your perusal here, although it does contain spoilers about things to come!
