D3D11 Texture Update Costs
As a continuation of what I’ve been working on, my glyph pages has been packed and allocated (I use Freetype to render the glyphs, although the shortfalls of that are probably worth another blog post), but I now need to render them.
Texture updating – the process of getting an image from RAM to a form that you can render – is one of those simple things that is full of pitfalls. It is also something which tends to be very API-specific, which, when you think about it, doesn’t even make sense. Anyway, I was reading one of the many talks about D3D11 buffer management (this one by AMD), and I came across an interesting slide:

Hmm! Some quite specific instructions there! Now I generally would like to believe these sort of recommendations (and, nVidia and AMD in particular know a lot about graphics hardware), but I’ve been developing stuff on iOS for multiple years now, and, well, let’s just say I’ve started taking suggestions from the vendors with several huge trucks of salt.
D3D Resource Updates
D3D10 and D3D11 are very expressive and powerful graphics APIs – providing a nice middle ground between console-like command buffers and D3D9 style intent based programming (OpenGL is even more removed from the hardware than D3D9, but manages to also be a disaster on every conceivable level). This sort of approach also strongly colours the ability to update objects in video memory. D3D provides a usage to objects at creation-time, where you can specify if the object is unchanging, or mappable by the CPU for reading/writing, etc. This leads into the final part of the puzzle – D3D allows address space to be mapped by the CPU for almost all resources (OGL allows you to do this for vertex/index buffers). It allows a more “traditional” approach – where you nominate a resource to be updated by some new data in RAM. Finally, resources in D3D may be copied to eachother to take advantage of the fastest available path.
Reading the slide above suggests that the correct approach is to keep a staging texture (staging textures in D3D can’t be used for rendering, but are optimized for CPU readbacks – if you want to get a screenshot, say, you would copy from the backbuffer to a staging texture, and then map that region of memory to get it out of the graphics API) around as your back buffer, and then use the CopyResource method to update the texture. What other alternatives are there?
First Principles: Recreate the Image
Let’s say you’re just starting out and getting things functioning. How bad would it be to simply recreate the texture from scratch? Surprisingly, the answer appears to be: not very. D3D texture creation looks like this:
// Release the old texture
m_Texture->Release();
D3D11_TEXTURE2D_DESC desc;
desc.Width = m_Width;
desc.Height = m_Height;
desc.MipLevels = 1; // no mipmaps
desc.ArraySize = 1;
desc.Format = DXGI_FORMAT_R8G8B8A8_UNORM;
desc.CPUAccessFlags = 0; // we won't be modifying this
desc.Usage = D3D11_USAGE_IMMUTABLE;
desc.MiscFlags = 0;
desc.SampleDesc.Count = 1; // no multisampling
desc.SampleDesc.Quality = 0;
desc.BindFlags = D3D11_BIND_SHADER_RESOURCE; // use for rendering
// Set up initial data
D3D11_SUBRESOURCE_DATA sr;
sr.pSysMem = m_ImageBuffer;
sr.SysMemPitch = m_Width * 4;
sr.SysMemSlicePitch = m_Width * m_Height * 4;
HRESULT hr = g_D3DDevice->CreateTexture2D(&tex, &sr, &m_Texture);
if (hr != S_OK)
Error("Abandon ship!");
// D3D also requires that the shader resource view be recreated next,
// but I have omitted it for brevity.
This approach has at least one benefit – it doesn’t create a dependency stall. By releasing the texture and making a new one, any in-flight commands referring to the old texture are safe to continue (the texture won’t be released until the driver frees it). Unfortunately, we have to copy over the whole image, even if we’ve only changed part of it – and we have to release and create 2 resources (the texture and the SRV).
UpdateSubResource
This is the technique closest to OpenGL – we create the texture as normal, and then update some part of it when we need to. We don’t know exactly what the driver will do – all we say is that we want this part of the texture to be replaced by that data. D3D allows us to update a texture which has been created a texture with the D3D11_USAGE_DEFAULT flag. The updater code is this:
D3D11_BOX box; box.front = 0; box.back = 1; box.left = 0; box.right = m_Width; box.top = 0; box.bottom = m_Height; g_D3DContext->UpdateSubresource(m_Texture, 0, &box, m_ImageBuffer, m_Width * 4, m_Width * m_Height * 4);
I also did a variant of this where I only updated either the actual dirty rectangle or the affected rows – approximately 1/10th and 1/5th of the texture, respectively.
Map/Unmap Texture
If we create the texture with the usage flags of D3D11_USAGE_DYNAMIC and the CPU access flags of D3D11_CPU_ACCESS_WRITE, we can use the Map/Unmap API to create an addressable region where we can simply memcpy our image into the texture. For ~*maximum performance*~ I’m using D3D11_MAP_DISCARD which will (hopefully) remove any stalls if the data is currently in flight (it does this by, essentially, making a new resource if there is some pipeline contention – ideally it should be a lighter weight version of recreating the texture).
D3D11_MAPPED_SUBRESOURCE mapped; g_D3DContext->Map(m_Texture, 0, D3D11_MAP_WRITE_DISCARD, 0, &mapped); // assume I'm checking that the mapped.RowPitch is m_Width * 4 here // protip: it is for my RGBA texture memcpy(mapped.pData, m_ImageBuffer, m_Width * m_Height * 4); g_D3DContext->Unmap(m_Texture, 0);
I couldn’t do a variant where I only copied the dirty region over – by using discard mapping I am required to provide all the data again, as there are no guarantees made about the area we don’t fill.
The Suggested Technique
For this technique, we create two textures – one (which we render with) with a usage flag of D3D11_USAGE_DEFAULT, and another with D3D11_USAGE_STAGING and CPU access flags of read and write. The update procedure consists of mapping the staging texture (you can use D3D11_MAP_READ_WRITE with staging textures), copying over the dirty region, and finishing with:
g_D3DContext->CopyResource(m_Texture, m_StagingTexture);
Or, just to copy the dirty region:
D3D11_BOX box; box.front = 0; box.back = 1; box.left = 0; box.right = m_Width; box.top = m_DirtyMinRow; box.bottom = m_DirtyMaxRow; g_D3DContext->CopySubresourceRegion(m_Texture, 0, 0, 0, 0, m_StagingTexture, 0, &box);
Staging Texture Variant – Permanent Mapping
There’s one more type to try – in all my examples I am copying from a memory buffer (m_ImageBuffer) into the texture – assumedly once per frame. This coalesces potentially a lot of updates (e.g., glyphs) into just one device update. But if we use a staging texture and keep it mapped permanently, we can drop the additional level of buffering. All texture writes will go directly to mapped memory, which will be unmapped, CopyResource’d and mapped again.
Results
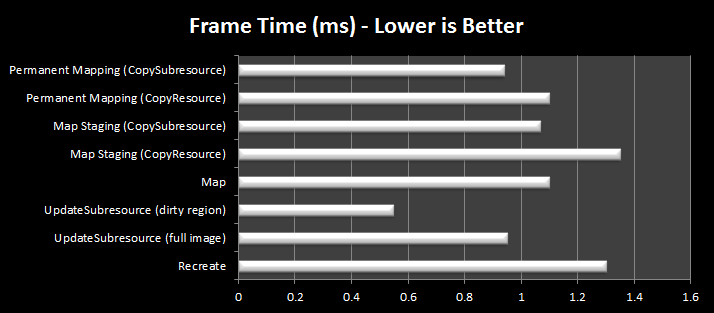
Oh. I guess the slow path isn’t so slow, hey.
That’s actually a little unfair – the test involves updating a 1024×1024 uncompressed RGBA texture, so we’re not dealing with a huge amount of data. We’re also not having to muck about with compressed formats, which have all kinds of weird packing rules, so please take these results with a grain of salt.
There’s one really big thing that I’m not doing, however, with makes it quite different.
How could AMD/nVidia be wrong?
Short answer: they aren’t – on average. My setup, which I did after years of writing graphics code, is already using a fairly fast path – the updates are all grouped at the start of a frame, and the rendering is done asynchronously from the client logic. By performing all my updates in a designated safe zone at the start of the frame, I ensure that the number of dependencies in the pipeline is as low as possible.
I went back to the testing program and purposely bypassed some of my infrastructure code to force a mid-frame update. Because the setup was generating the same data every frame (I was clearing the glyph buffer and rendering the same text), it actually still looked the same – but half the rendered text was from the pre-updated texture, and half from the updated image. The results are quite different.
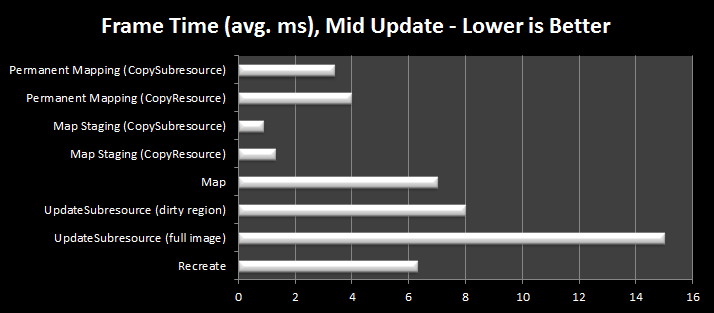
Note that the scale is literally 10x bigger than the last chart
Whoa! Suddenly it looks like the guidelines are spot on. Of particular interest is that UpdateSubresource, our previous winner, is now about 8x slower than the staging texture solution. Keeping the staging texture mapped seems to also be a bad idea – although that may just be an anomaly of my testing set up. If I was to make some wild stabs in the dark I’d say that the immediate re-mapping of the staging image introduces a stall – the target texture has to be updated before I start writing to the staging texture memory, but it may be in use by the hardware.
The same sort of thing is happening all over – any sort of update has to wait for the hardware to finish doing what it has in-flight with the texture. I assume that by CopyResource-ing from the staging texture either the driver is doing a rename (like MAP_DISCARD) or it just pipelines it effectively (since we are not re-mapping the stage texture immediately).
This second chart also does not convey the enormous variance of the results – unlike the first test, where every time didn’t vary by more than 5%, I was seeing frame times fluctuating wildly from <1ms to over 40ms, for all the methods tested except the copy from staging – making it a clear winner over the other options.
Conclusion
If you’re updating your textures mid-frame, use a staging texture to do it! Actually a better conclusion is that you shouldn’t update resources mid-frame, if possible. I know that’s often an impossible task, but at the very least you can minimize in-flight updates. It seems to be more of an issue for textures – I suppose it’s far more typical to update a vertex buffer or an index buffer which is in-use.
Finally, when you update your textures, just update the dirty rows! There are consistent speed benefits for avoiding copying more than is necessary. I couldn’t see any difference between updating whole or partial rows, but I suspect that’s because my 1024×1024 texture has a row size of exactly one memory page, and mapped resources create write-combining memory, where the modified pages are copied back to the driver.
I haven’t done enough profiling, but this may also have implications for OpenGL. In OGL, you would generally update an image using glTexSubImage2D rather than clobbering the texture entirely (via glTexImage2D). This maps directly to the UpdateSubresource path in D3D, so I one would expect that an in-flight update is either going to have a large performance cost, or will be hidden/”reinterpreted” by the driver (which tends to happen with OpenGL).
Bonus Extra Conclusion
There are a few other things going on here – we could try double-buffering the rendered texture (to avoid stalls), or we could see what happens if you do multiple updates per frame. I suspect the answer will remain the same – don’t update things that are in flight. Adding an extra buffer may fix one stall, but then if your architecture allows multiple in-frame updates, you are simply pushing the problem to the second time you do an update. It is possible that with the suggested usage pattern with a staging texture, you may be able to sweep some of those stalls under the rug, so to speak – provided you do enough work between updates, however it was beyond the scope of my investigation to test that.
